



Last updated on May 15th, 2026 at 02:58 pm
Data science is an in-demand career path for people who have a knack for research, programming, computers and maths. It is an interdisciplinary field that uses algorithms and other procedures for examining large amounts of data to uncover hidden patterns to generate insights and direct decision-making.
Let us learn in detail about the core values of data science and analytics along with different aspects of how to create a career in data science with the best data science training.
What is Data Science?
Data science is a study of data where data scientists construct specific forms of questions around specific data sets. After that, they use data analytics to find patterns and create a predictive model for developing fruitful insights that would facilitate the decision-making of a business.
The Role of Data Analytics in Decision-Making
Data Analytics plays a crucial role in the field of decision-making. It involves the process of examining and interpreting data to gain valuable insights for strategic operations and decisions in various domains. Here are some key ways in which data analytics influence the decision-making procedure.
- Data analytics helps organisations to analyse various historical data and current trends with scrutiny and enables them to decipher what has happened before and how they can improve it in their present operations. It provides a robust foundation when it comes to making informed decisions.
- Through data analytics, it becomes easier to understand the patterns and trends in large data sets. Hence recognising these patterns helps the business to capitalise on various opportunities or identify potential threats in the business.
Data Science vs. Data Analytics: Understanding the Differences
Data science and data analytics are closely related fields. However, they have distinct roles and methodologies. Let us see what they are:
| Characteristics | Data Science | Data Analytics |
| Purpose | Data science is a multidisciplinary field that deals with domain expertise, programming skills, and statistical knowledge from data. The primary goal here is to discover patterns and build predictive models. | Data analytics focuses on analysing data to understand the state of affairs and make data-driven decisions. It incorporates various tools and techniques to process, clean and visualise data for descriptive and diagnostic purposes. |
| Scope | Data science encompasses a wide range of activities including data preparation, data cleaning, machine learning and statistical analysis. Data scientists work on complicated projects requiring a deep understanding of mathematical concepts and algorithms. | Data analytics is focused more on a descriptive and diagnostic analysis involving examining historical data and applying various statistical methods to know its performance metrics. |
| Business Objectives | Data science projects are driven primarily by strategic business objectives to behave customer behaviour and identify growth opportunities. | Data analytics is primarily focused on solving immediate problems and answering specific questions based on available data. |
| Data Volume and Complexity | Data science deals with large complex data sets that require advanced algorithms. It is distributed among the computing techniques that process and analyse data effectively. | Data analytics tends to work with smaller datasets and does not require the same level of computational complexity as data science projects. |
Applications of Data Science and Analytics in Various Industries
Healthcare
- Predictive analysis is used for early detection of diseases and patient risk assessment.
- Data-driven insights that improve hospital operations and resource allocation.
- Medical image analysis helps in diagnosing conditions and detecting various anomalies.
Finance
- Credit risk assessments and fraud detections are done by using machine learning algorithms.
- Predictive modelling for investment analysis and portfolio optimisation.
- Customer segmentation and personalised financial recommendations.
Retail
- Recommender systems with personalised product recommendations.
- Market-based analysis for understanding inventory by looking through the buying patterns.
- Demand forecasting methods to ensure that the right products are available at the right time.
Data Sources and Data Collection
Types of Data Sources
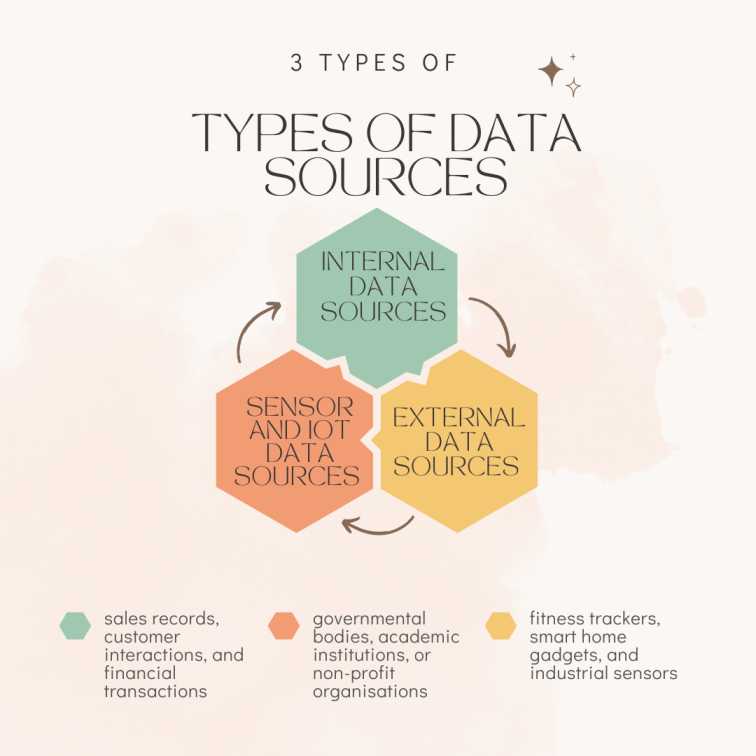
The different locations or points of origin from which data might be gathered or received are referred to as data sources. These sources can be roughly divided into many groups according to their nature and traits. Here are a few typical categories of data sources:
Internal Data Sources
- Data is generated through regular business operations, such as sales records, customer interactions, and financial transactions.
- Customer data is information gathered from user profiles, reviews, and online and mobile behaviours.
- Information about employees, such as their work history, attendance patterns, and training logs.
External Data Sources
- Publicly available data that may be accessed by anyone, is frequently offered by governmental bodies, academic institutions, or non-profit organisations.
- Companies that supply specialised datasets for certain markets or uses, such as market research data, demographic data, or weather data.
- Information gathered from different social media sites includes user interactions, remarks, and trends.
Sensor and IoT Data Sources
- Information is gathered by sensors and connected devices, including wearable fitness trackers, smart home gadgets, and industrial sensors.
- Information is collected by weather stations, air quality monitors, and other environmental sensors that keep tabs on several characteristics.
Data Preprocessing and Data Cleaning
Data Cleaning Techniques
A dataset’s flaws, inconsistencies, and inaccuracies are found and fixed through the process of data cleaning, sometimes referred to as data cleansing or data scrubbing. Making sure that the data utilised for analysis or decision-making is correct and dependable is an essential stage in the data preparation process. Here are a few typical methods for cleaning data:
Handling Missing Data
- Imputation: Substituting approximated or forecasted values for missing data using statistical techniques like mean, median, or regression.
- Removal: If it doesn’t negatively affect the analysis, remove rows or columns with a substantial amount of missing data.
Removing Duplicates
- Locating and eliminating duplicate records to prevent analysis bias or double counting.
Outlier Detection and Treatment
- Help identify the outliners and make an informed decision as required in the data analysis.
Data Standardisations
- Ensures consistent units of measurement, representation and formatting across the data sets.
Data Transformation
- Converting data for a feasible form to perform data analysis to ensure accuracy.
Data Integration and ETL (Extract, Transform, Load)
Data Integration
Data integration involves multiple data being combined in a unified manner. This is a crucial process in an organisation where data is stored in different databases and formats which need to be brought together for analysis. Data integration aims to remove data silos ensuring efficient decision-making with data consistency.
ETL (Extract, Transform, Load)
Data extraction from diverse sources, format conversion, and loading into a target system, like a data warehouse or database, are all steps in the data integration process known as ETL. ETL is a crucial step in ensuring data consistency and quality throughout the integrated data. The three stages of ETL are
- Extract: Data extraction from various source systems, which may involve reading files, running queries against databases, web scraping, or connecting to APIs.
- Transform: Putting the collected data into a format that is consistent and standardised. Among other processes, this step involves data cleansing, data validation, data enrichment, and data aggregation.
- Load: Transformed data is loaded into the target data repository, such as a database or data warehouse, to prepare it for analysis or reporting.
Exploratory Data Analysis (EDA)
Understanding EDA and its Importance
Exploratory data analysis, often known as EDA, is a key first stage in data analysis that entails visually and quantitatively examining a dataset to comprehend its structure, trends, and properties. It seeks to collect knowledge, recognise trends, spot abnormalities, and provide guidance for additional data processing or modelling stages. Before creating formal statistical models or drawing conclusions, EDA is carried out to help analysts understand the nature of the data and make better decisions.
Data Visualisation Techniques
Data visualisation techniques are graphically represented to visually explore, analyse and communicate various data patterns and insights. It also enhances the comprehension of complex datasets and facilitates proper data-driven decision-making. The common data visualisation techniques are
- Bar graphs and column graphs.
- Line charts.
- Pie charts.
- Scatter plots.
- Area charts.
- Histogram.
- Heatmaps.
- Bubble charts.
- Box plots.
- Treemaps.
- Word clouds.
- Network graphs.
- Choropleth maps.
- Gantt charts.
- Sankey diagrams.
- Parallel Coordinates.
- Radar charts.
- Streamgraphs.
- Polarcharts.
- 3D charts.
Descriptive Statistics and Data Distribution
Descriptive Statistics
Descriptive statistics uses numerical measures to describe the various datasets succinctly. They help in providing a summary of data distribution and help to understand the key properties of data without conducting a complex analysis.
Data Distribution
The term “data distribution” describes how data is split up or distributed among various values in a dataset. For choosing the best statistical approaches and drawing reliable conclusions, it is essential to comprehend the distribution of the data.
Identifying Patterns and Relationships in Data
An essential part of data analysis and machine learning is finding patterns and relationships in data. You can gather insightful knowledge, form predictions, and comprehend the underlying structures of the data by seeing these patterns and linkages. Here are some popular methods and procedures to help you find patterns and connections in your data:
Start by using plots and charts to visually explore your data. Scatter plots, line charts, bar charts, histograms, and box plots are a few common visualisation methods. Trends, clusters, outliers, and potential correlations between variables can all be seen in visualisations.
To determine the relationships between the various variables in your dataset, compute correlations. When comparing continuous variables, correlation coefficients like Pearson’s correlation can show the strength and direction of associations.
Use tools like clustering to find patterns or natural groupings in your data. Structures in the data can be found using algorithms like k-means, hierarchical clustering, or density-based clustering.
Analysing high-dimensional data can be challenging. You may visualise and investigate correlations in lower-dimensional areas using dimensionality reduction techniques like Principal Component Analysis (PCA) or t-distributed Stochastic Neighbour Embedding (t-SNE).
Data Modeling, Data Engineering, and Machine Learning
Introduction to Data Modeling
The technique of data modelling is essential in the area of information systems and data management. To enable better comprehension, organisation, and manipulation of the data, it entails developing a conceptual representation of the data and its relationships. Making informed business decisions, creating software applications, and designing databases all require data modelling.
Data modelling is a vital procedure that aids organisations in efficiently structuring their data. It helps with the creation of effective software programmes, the design of strong databases, and the maintenance of data consistency across systems. The basis for reliable data analysis, reporting, and well-informed corporate decision-making is a well-designed data model.
Data Engineering and Data Pipelines
Data Engineering
Data engineering is the process of building and maintaining the infrastructure to handle large volumes of data efficiently. It involves various tasks adhering to data processing and storage. Data engineers focus on creating a reliable architecture to support data-driven applications and analytics.
Data Pipelines
Data pipelines are a series of automated procedures that move and transform data from one stage to another. They provide a structured flow of data that enables data processing and delivery in various destinations easily. Data pipelines are considered to be the backbone of data engineering that helps ensure a smooth and consistent data flow.
Machine Learning Algorithms and Techniques
In data-driven decision-making automation, machine learning algorithms and techniques are extremely crucial. They allow computers to learn various patterns and make predictions without any explicit programming. Here are some common machine-learning techniques. They are:
- Linear Regression: This is used for predicting continuous numerical values based upon its input features.
- Logistic Regression: This is primarily used for binary classification problems that predict the probabilities of class membership.
- Hierarchical Clustering: Agglomerative or divisive clustering based upon various hierarchical relationships.
- Q-Learning: A model-free reinforcement learning algorithm that estimates the value of taking particular actions in a given state.
- Transfer Learning: Leverages knowledge from one task or domain to improve performances on related tasks and domains.
Big Data and Distributed Computing
Introduction to Big Data and its Challenges
Big Data is the term used to describe enormous amounts of data that are too complex and huge for conventional data processing methods to effectively handle. The three Vs—Volume (a lot of data), Velocity (fast data processing), and Variety (a range of data types—structured, semi-structured, and unstructured)—define it. Data from a variety of sources, including social media, sensors, online transactions, videos, photos, and more, is included in big data.
Distributed Computing and Hadoop Ecosystem
Distributed Computing
A collection of computers that work together to complete a given activity or analyse huge datasets is known as distributed computing. It enables the division of large jobs into smaller ones that may be done simultaneously, cutting down on the total computing time.
Hadoop Ecosystem
Hadoop Ecosystem is a group of free and open-source software programmes that were created to make distributed data processing and storage easier. It revolves around the Apache Hadoop project, which offers the Hadoop Distributed File System (HDFS) and the MapReduce framework for distributed processing.
Natural Language Processing (NLP) and Text Analytics
Processing and Analysing Textual Data
Natural language processing (NLP) and data science both frequently use textual data for processing and analysis. Textual information can be available is available blog entries, emails, social network updates etc. There are many tools, libraries, and methodologies available for processing and deriving insights from text in the rich and developing field of textual data analysis. It is essential to many applications, such as sentiment analysis, consumer feedback analysis, recommendation systems, chatbots, and more.
Sentiment Analysis and Named Entity Recognition (NER)
Sentiment Analysis
Finding the sentiment or emotion expressed in a text is a method known as sentiment analysis, commonly referred to as opinion mining. It entails determining if a good, negative, or neutral attitude is being expressed by the text. Numerous applications, including customer feedback analysis, social media monitoring, brand reputation management, and market research, heavily rely on sentiment analysis.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is a subtask of information extraction that involves the identification and classification of specific entities such as the names of people, organisations, locations, dates, etc. from pieces of text. NER is crucial for understanding the structure and content of text and plays a vital role in various applications, such as information retrieval, question-answering systems, and knowledge graph construction.
Topic Modeling and Text Clustering
Topic Modelling
To find abstract “topics” or themes in a group of papers, a statistical technique is called topic modelling. Without a prior understanding of the individual issues, it enables us to comprehend the main topics or concepts covered in the text corpus. The Latent Dirichlet Allocation (LDA) algorithm is one of the most frequently used methods for topic modelling.
Text Clustering
Based on their content, comparable papers are grouped using a technique called text clustering. Without having any prior knowledge of the precise categories, it seeks to identify organic groups of documents. Large datasets can be organised and their patterns can be found with the aid of clustering.
Time Series Analysis and Forecasting
Understanding Time Series Data
Each data point in a time series is connected to a particular timestamp and is recorded throughout a series of periods. Numerous disciplines, such as economics, weather forecasting, and IoT (Internet of Things) sensors, use time series data. Understanding time series data is crucial for gaining insightful knowledge and for developing forecasts on temporal trends.
Time Series Visualisation and Decomposition
Understanding the patterns and components of time series data requires the use of time series visualisation and decomposition techniques. They aid in exposing trends, seasonality, and other underlying structures that can help with data-driven decision-making and value forecasting in the future.
Moving averages, exponential smoothing, and sophisticated statistical models like STL (Seasonal and Trend decomposition using Loess) are just a few of the strategies that can be used to complete the decomposition process.
Analysts can improve forecasting, and decision-making by visualising data to reveal hidden patterns and structures. These methods are essential for time series analysis in economics, healthcare, finance, and environmental studies.
Forecasting Techniques (ARIMA, Exponential Smoothing, etc.)
To forecast future values based on historical data and patterns, forecasting techniques are critical in time series analysis. Here are a few frequently used forecasting methods:
- Autoregressive Integrated Moving Average (ARIMA): This time series forecasting technique is well-liked and effective. To model the underlying patterns in the data, it mixes moving averages (MA), differencing (I), and autoregression (AR). ARIMA works well with stationary time series data, where the mean and variance don’t change over the course of the data.
- Seasonal Autoregressive Integrated Moving Average (SARIMA): An expansion of ARIMA that takes the data’s seasonality into consideration. In order to deal with the periodic patterns shown in the time series, it also contains additional seasonal components.
- Exponential smoothing: A family of forecasting techniques that gives more weight to new data points and less weight to older data points is known as exponential smoothing. It is appropriate for time series data with seasonality and trends.
- Time series decomposition by season (STL): Time series data can be broken down into their trend, seasonality, and residual (noise) components using the reliable STL approach. When dealing with complicated and irregular seasons, it is especially helpful.
Real-World Time Series Analysis Examples
Finance: The process of predicting the future, spotting patterns, and supporting investment decisions by analysing stock market data, currency exchange rates, commodity prices, and other financial indicators.
Energy: Planning for peak demand, identifying energy-saving options, and optimising energy usage all require analysis of consumption trends.
Social Media: Examining social media data to evaluate company reputation, spot patterns, and comprehend consumer attitude.
Data Visualisation and Interactive Dashboards
Importance of Data Visualisation in Data Science
For several reasons, data visualisation is essential to data science. It is a crucial tool for uncovering and sharing intricate patterns, trends, and insights from huge datasets. The following are some of the main justifications for why data visualisation is so crucial in data science:
- Data visualisation enables data scientists to visually explore the data, that might not be visible in the raw data.
- It is simpler to spot significant ideas and patterns in visual representations of data than in tabular or numerical forms. When data is visualised, patterns and trends are easier to spot.
- Visualisations are effective tools for explaining difficult information to stakeholders of all technical backgrounds. Long reports or tables of figures cannot express insights and findings as clearly and succinctly as a well-designed visualisation.
Visualisation Tools and Libraries
For making intelligent and aesthetically pleasing visualisations, there are several potent tools and packages for data visualisation. Among the well-liked ones are:
- A popular Python charting library is Matplotlib. It provides a versatile and extensive collection of features to build all kinds of static, interactive, and publication-quality visualisations.
- Seaborn, a higher-level interface for producing illuminating statistical visuals, is developed on top of Matplotlib. It is very helpful for making appealing visualisations with little coding and for visualising statistical correlations.
- Tableau is an effective application for data visualisation that provides interactive drag-and-drop capability to build engaging visualisations. It is widely used in many industries for data exploration and reporting.
Interactive Dashboards and Custom Visualisations
Interactive Dashboards
Users can interact with data visualisations and examine data via interactive dashboards, which include dynamic user interfaces. They often include numerous graphs, tables, charts, and filters to give a thorough overview of the data.
Custom Visualisation
Data visualisations that are developed specifically for a given data analysis purpose or to present complex information in a more understandable way are referred to as custom visualisations. Custom visualisations are made to fit particular data properties and the targeted objectives of the data study.
Communicating Data Insights through Visuals
A key competency in data analysis and data science is the ability to convey data insights through visualisations. It is simpler for the audience to act on the insights when complicated information is presented clearly through the use of well-designed data visualisations. In a variety of fields, such as business, research, and academia, effective data visualisations can result in better decision-making, increased understanding of trends, and improved findings.
Data Ethics, Privacy, and Security
Ethical Considerations in Data Science
To ensure ethical and socially acceptable usage of data, data science ethics are essential. It is critical to address ethical issues and ramifications as data science develops and becomes increasingly important in many facets of society.
The ethical development of data science is essential for its responsible and long-term sustainability. Professionals may leverage the power of data while preserving individual rights and the well-being of society by being aware of ethical concepts and incorporating them into every step of the data science process. A constant exchange of ideas and cooperation among data scientists, ethicists, decision-makers, and the general public is also essential for resolving new ethical issues in data science.
Data Privacy Regulations (e.g., GDPR)
A comprehensive data protection law known as GDPR went into force in the European Union (EU) on May 25, 2018. Regardless of where personal data processing occurs, it is governed by this law, which applies to all EU member states. People have several rights under GDPR, including the right to view, correct, and delete their data. To secure personal data, it also mandates that organisations get explicit consent and put in place strong security measures.
Organisations that gather and use personal data must take these restrictions into account. They mandate that businesses disclose their data practises in full, seek consent when it’s required, and put in place the essential security safeguards to safeguard individuals’ data. Organisations may incur hefty fines and reputational harm for failing to abide by data privacy laws. More nations and regions are enacting their own data protection laws to defend people’s rights to privacy as concerns about data privacy continue to rise.
Data Security and Confidentiality
Protecting sensitive information and making sure that data is secure from unauthorised access, disclosure, or alteration require strong data security and confidentiality measures. Data security and confidentiality must be actively protected, both by organisations and by individuals.
It takes regular monitoring, updates, and enhancements to maintain data security and secrecy. Organisations may safeguard sensitive information and preserve the confidence of their stakeholders and consumers by implementing a comprehensive strategy for data security and adhering to best practices.
Fairness and Bias in Machine Learning Models
Fairness and bias in machine learning models are essential factors to take into account to make sure that algorithms don’t act biasedly or discriminate against specific groups. To encourage the ethical and responsible use of machine learning in many applications, it is crucial to construct fair and unbiased models.
Building trustworthy and ethical machine learning systems requires taking into account fairness and prejudice. It is crucial to be aware of the ethical implications and work towards just and impartial AI solutions as AI technologies continue to be incorporated into a variety of fields.
Conclusion
To sum up, data science and analytics have become potent disciplines that take advantage of the power of data to provide insights, guide decisions, and bring about transformational change in a variety of industries. For businesses looking to gain a competitive advantage and improve efficiency, data science integration into business operations has become crucial.
If you are interested in looking for a data analyst course or data scientist course with placement, check out Imarticus Learning’s Postgraduate Programme in Data Science and Analytics. This data science course will help you get placed in one of the top companies in the country. These data analytics certification courses are the pinnacle of building a new career in data science.
To know more or look for more business analytics course with placement, check out the website right away!