


Last updated on May 15th, 2026 at 03:07 pm
Keeping data right is very important for all databases. When we have copies, it can cause problems and use more space. To help with this, we will learn how to delete duplicate rows in SQL. We’ll start with simple ways and work up to complicated ones.
We’ll explore a range of techniques, from the fundamental DISTINCT keyword to utilising advanced Common Table Expressions (CTEs) in conjunction with the ROW_NUMBER() function. I’ve found that mastering these technicalities is usually the first step for anyone taking a professional data analytics course, as it shifts your focus from just “writing code” to maintaining the high-standard environments required in modern business. This will make you adapt to using SQL and keep your data clean and efficient in no time!
I’ve noticed that in 2026, simply having “clean” data isn’t enough to impress the higher-ups.
According to recent industry shifts, SQL for data analysis has become the bread and butter of the modern workplace, with over 90% of enterprise-level applications still relying on SQL for mission-critical consistency (Source: IMARC Group).
As Edward Tufte famously noted in The Visual Display of Quantitative Information,
“Confusion and clutter are failures of design, not attributes of information.”
This is why I always say that knowing how to visualise SQL data is just as vital as knowing how to query it; if your data is a mess of duplicates, your SQL visualisations will be too. Duplicate rows in SQL can break your analysis, slow down queries, and lead to wrong insights. In this guide, you’ll learn 5 proven ways to find and delete duplicate rows in SQL using real examples – so you can clean your data quickly and confidently.
What are Duplicate Rows in SQL?
Duplicate rows in SQL refer to particular records in a table that contain identical values across many columns. These duplicates can occur due to improper data entry, lack of constraints, or errors during data imports and joins.
For example, if a customer table stores the same customer details multiple times, it creates redundancy and affects data accuracy.
Why Are Duplicate Rows Dangerous?
Duplicate data isn’t just messy – it directly impacts performance and decision-making:
- Incorrect analysis: Reports and dashboards may show inflated results.
- Slower queries: Larger datasets increase processing time.
- Storage waste: Unnecessary duplication consumes database space.
- Data inconsistency: Multiple versions of the same record create confusion.
In short, duplicate rows reduce both data reliability and system efficiency.
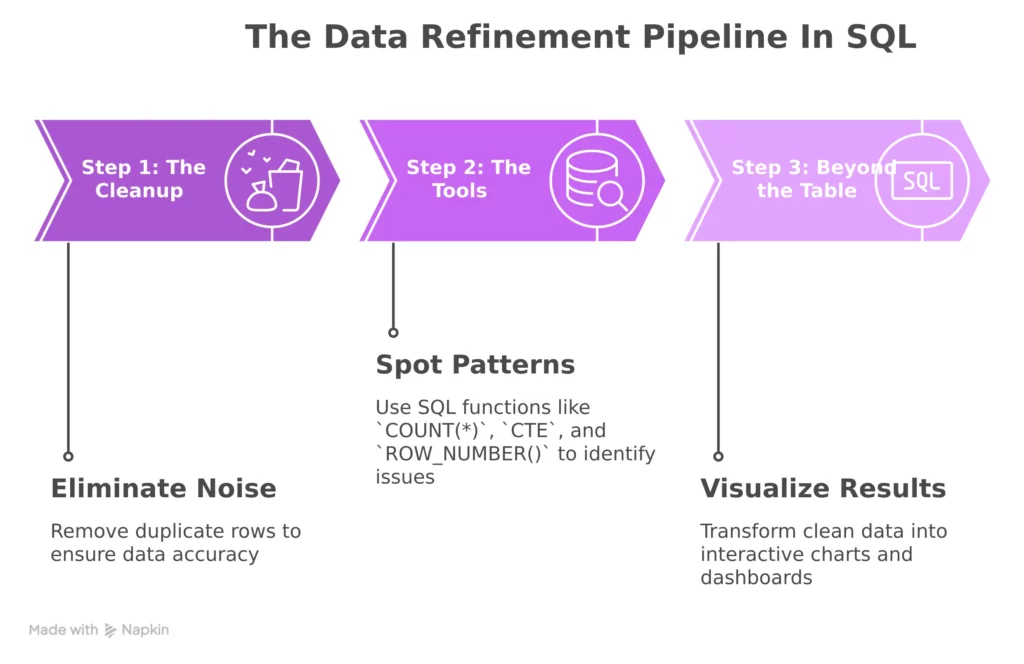
In brief, this is what the SQL data refinement process looks like in simple words.
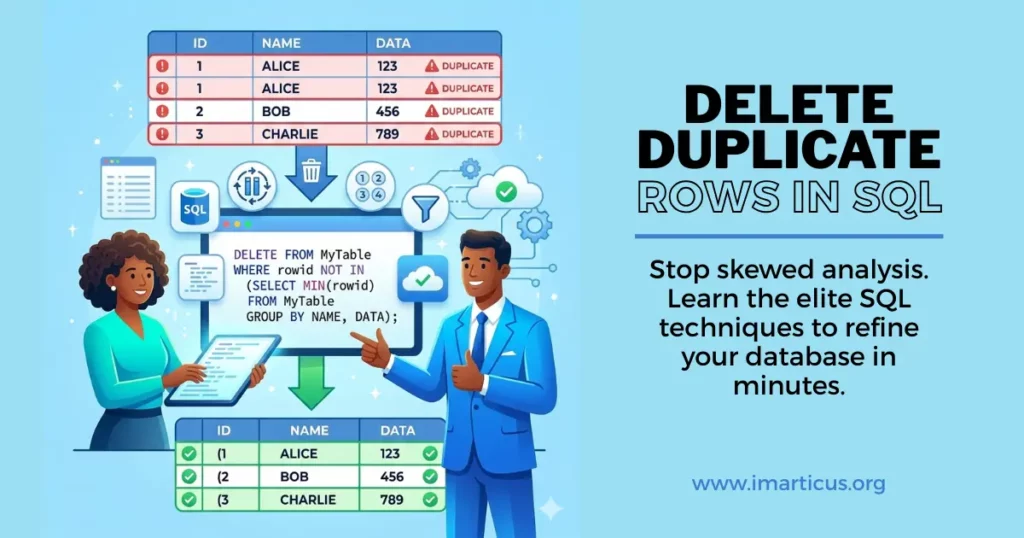
Delete Duplicate Rows in SQL
In SQL, deleting duplicate rows means removing entries from a table that contain equal information based on specific criteria. Duplicate rows can occur for diverse reasons, including data entry mistakes, integrations from different assets, or incomplete deduplication methods.
Deleting duplicates facilitates:
| Improved data integrity | Saved storage space | Enhanced data analysis |
| By eliminating redundant data, you make sure that the tables are correctly filled with data and consistent. | Duplicate rows occupy needless garage space, and getting rid of them can optimise database performance. | Duplicate rows can skew the statistics evaluation. Removing them results in more correct and dependable insights. |
Delete Duplicate Rows in SQL – Quick Methods
- Use GROUP BY to identify duplicates.
- Use ROW_NUMBER() to delete duplicates safely.
- Use CTE for clean and scalable queries.
- Use Self Join for direct comparison.
- Use DISTINCT to rebuild clean tables.
How to Delete Duplicate Rows in SQL Using Sample Data
Here’s how testing makes it clear to see how duplicate rows take-out works in SQL.
Sample data
Let’s consider a table named Customers with the following columns:
| CustomerID | Name | |
| 1 | John Doe | john.doe@email.com |
| 2 | Jane Smith | jane.smith@email.com |
| 3 | Mike Jones | mike.jones@email.com |
| 4 | John Doe | john.doe@email.com (duplicate) |
This table has the same row twice for John Doe. We can take an example like this to show how various SQL ways find and delete duplicate rows.
Delete Duplicate Rows in SQL Using Group
Using GROUP BY and HAVING clauses is a strong method to remove repeated rows in SQL. You select columns to group the data and then use the HAVING clause to filter the groups. It helps find rows with the same values in specific columns.
Here’s how it works:
- Group By: You choose which columns to group the data by. This puts rows with the same values in those columns into categories.
- HAVING Clause: This filters the groups made by GROUP BY. You can use COUNT(*) inside HAVING to find groups with more than one row (copies).
Did you know?
Data scientists still spend roughly 80% of their time on data preparation and cleaning – including the tedious task of deleting duplicate rows in SQL – leaving only 20% for actual analysis and modeling. (Source: Forbes)
How to Delete Duplicate Rows in SQL With Group by and Having
To delete duplicate rows in SQL, follow the steps mentioned here.
DELETE FROM your_table_name
WHERE your_table_name.column_name_1 IN (
SELECT column_name_1
FROM your_table_name
GROUP BY column_name_1, column_name_2 (columns for duplicate check)
HAVING COUNT(*) > 1
);Example
Consider a table named Products with columns ProductCode, ProductName, and Price. We want to delete duplicate products based on ProductCode and Price.
DELETE FROM Products
WHERE Products.ProductCode IN (
SELECT ProductCode
FROM Products
GROUP BY ProductCode, Price
HAVING COUNT(*) > 1
);Result: This query will put things together by ProductCode and Price. The part saying HAVING COUNT(*) > 1 shows sets with the same products and prices. The DELETE statement then takes away rows with codes that are the same as those found in duplicates.
Fetching and Identifying the Duplicate Rows in SQL
It’s crucial to identify them accurately before knowing how to remove duplicates in SQL. Data science professionals often use SQL’s functionalities like querying and filtering to pinpoint these duplicate entries. Here are some methods to fetch and identify duplicate rows:
Method 1: Using GROUP BY and COUNT(*)
For any SQL for data analysis task, I start by ensuring my primary keys are actually unique. This is a common approach that uses both grouping and aggregate functions. The idea is to group rows based on the columns that define duplicates.
Use COUNT(*) to determine the number of rows in each group. Groups with a count greater than 1 indicate duplicates.
Syntax
SELECT column_name_1, column_name_2, ..., COUNT(*) AS row_count
FROM your_table_name
GROUP BY column_name_1, column_name_2, ...;Method 2: Using DISTINCT and Self-Join
The SQL remove duplicates option is a very handy way to handle your data. This method utilises DISTINCT to fetch unique combinations and a self-join to compare rows.
- Use SELECT DISTINCT on the columns defining duplicates to get unique combinations.
- Later on, perform a self-join on the table itself, matching these unique combinations with the original table.
If you need a lightweight way to share results, some SQL visualisation tools even allow you to export a SQL SVG for web reports.
Syntax
SELECT t1*.
FROM (SELECT DISTINCT column_name_1, column_name_2, ... FROM your_table_name) AS unique_data
INNER JOIN your_table_name AS t1 ON (unique_data.column_name_1 = t1.column_name_1 AND ...)
WHERE unique_data.column_name_1 = t1.column_name_1 AND ...;Method 3: Using ROW_NUMBER()
As an SQL for business analyst, your goal isn’t just to ‘delete rows’ but to provide a clear SQL to chart pipeline. This method assigns a row number within groups defined by duplicate criteria, allowing you to identify duplicates based on their order.
Syntax
SELECT *, ROW_NUMBER() OVER (PARTITION BY column_name_1, column_name_2, ... ORDER BY column_name_3) AS row_num
FROM your_table_name;How Do You Choose the Right Method?
The right way depends on your needs and table size. Using GROUP BY and COUNT(*) is good for most cases.
- If you know how to remove duplicates in SQL, you might as well learn when to use which method.
- If you have complicated copies or need to filter based on order, you could try ROW_NUMBER().
- If you want to see all the copies, using a self-join can help.
Once I’ve scrubbed my tables clean, I don’t just stop at the terminal. I often move straight into data visualisation with SQL to spot any remaining outliers. If you’re wondering, “How do I build charts with drilldown and dynamic filtering capabilities?” or “Which dashboard includes built-in SQL analysis tools?“, the answer usually lies in integrating your database with a SQL visualiser like Tableau or Power BI.
Using a SQL query visualisation tool helps me see patterns that a wall of text might hide. For those of us in the trenches, visualising SQL queries isn’t just a fancy extra – it’s how we explain our findings to stakeholders who don’t speak code.
Delete Duplicate Rows in SQL With an Intermediate Table
The “Intermediate table” way is good for doing away with the same rows in SQL. You use another table to keep the different info, and then swap it with the first table. For example, in a table called Customers with CustomerID, Name, and Email, with the same data.
I’ve found that the best way to explore data using SQL interfaces is to first clean the duplicates so my SQL chart sheet remains accurate.
Steps to delete duplicate rows in SQL with an intermediate table
- Create Intermediate Table: CREATE TABLE Customers_Temp LIKE Customers;
- Insert Distinct Rows: INSERT INTO Customers_Temp
- SELECT DISTINCT CustomerID, Name, Email
- FROM Customers;
- (Optional) Drop Original Table: DROP TABLE Customers;
- Rename Intermediate Table: ALTER TABLE Customers_Temp RENAME TO Customers;
Also Read: Why you should know the difference between SQL and MySQL.
Deleting Duplicate Rows in SQL Using ROW_NUMBER() Function
The ROW_NUMBER() function is a handy tool for deleting duplicate rows within a database table. For a query to delete duplicate records in SQL, you have a convenient option in this function. This function assigns a unique number to each row within a result set, based on a specified ordering.
It uses the following syntax:
ROW_NUMBER() OVER (PARTITION BY <column_list> ORDER BY <column_list>) AS row_num
where
- PARTITION BY <column_list>: This clause groups rows together based on the specified columns. Rows within each group will be assigned unique row numbers.
- ORDER BY <column_list>: This clause defines the order in which the rows within each partition will be numbered.
Example
Suppose you have a table named Customers with columns customer_id, name, and email. You want to delete duplicate customer entries based on name and email. Here’s the query:
WITH cte AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY name, email ORDER BY customer_id) AS row_num
FROM Customers
)
DELETE FROM cte
WHERE row_num > 1;Result: This query first creates a CTE named cte. It assigns a row number (row_num) to each row in the Customers table. The partitioning is done by name and email, and the ordering is based on customer_id. Then, the DELETE statement removes rows from the CTE where row_num is greater than 1, eliminating duplicates.
Delete Duplicate Rows in SQL Using Common Table Expressions (CTE)
Common Table Expressions (CTEs) offer a powerful way to delete duplicate rows from your database tables. When I visualise SQL database structures, I often spot redundant joins that can be fixed with a clean CTE.
Here’s how you can use CTEs with the ROW_NUMBER() function for this task:
Step 1. Define the CTE
- The CTE identifies the duplicate rows. Here, you’ll use the ROW_NUMBER() function to assign a unique sequential number to each row.
- The PARTITION BY clause groups rows together based on specific columns. Only rows within the same group will compete for unique numbering.
- The ORDER BY clause defines the order in which rows within each group are numbered.
Step 2. Filter and delete
After creating the CTE, you can use the DELETE statement to target the CTE alias. Within the DELETE statement, you’ll filter for rows where the ROW_NUMBER() (often aliased as row_num) is greater than 1. This effectively removes duplicates while keeping the first occurrence of each unique combination.
Fact!
43% of chief operations officers identify data quality issues as their most significant data priority! (Source: A 2025 report by the IBM Institute for Business Value (IBV))
How to Delete Duplicate Rows in SQL Using CTE
While procedures are a great way to encapsulate logic, removing duplicates with CTEs is typically done within a single SQL statement. However, here’s how you could potentially create a procedure using CTEs as an example:
Step 1. Procedure creation
CREATE PROCEDURE RemoveDuplicates (
@tableName VARCHAR(50), -- Name of the table to process
@columnList VARCHAR(200) -- Comma-separated list of columns for duplicate check
)
AS
BEGIN
-- Implement the logic here
END;Step 2. Logic within the procedure (using CTE)
DECLARE @cteName VARCHAR(50); -- To store dynamic CTE name
SET @cteName = 'cte_' + @tableName; -- Generate unique CTE name
WITH (@cteName) AS ( -- Define CTE dynamically
SELECT *,
ROW_NUMBER() OVER (PARTITION BY @columnList ORDER BY some_column) AS row_num
FROM @tableName
)
DELETE FROM @cteName -- Delete from CTE
WHERE row_num > 1;
END;| Method | Best For | Difficulty |
|---|---|---|
| GROUP BY | Small datasets | Easy |
| ROW_NUMBER | Large datasets | Medium |
| CTE | Clean queries | Medium |
Also Read: How mastering the basics of SQL can help you in a Database Management and Analytics career.
Rank Function to SQL Delete Duplicate Rows
The RANK() function in SQL can be a great tool for deleting duplicate rows from a table. The function assigns a ranking number to each row within a result set, considering a specified ordering. Similar to ROW_NUMBER(), it uses the following syntax:
RANK() OVER (PARTITION BY <column_list> ORDER BY <column_list>) AS rank_num
where
- PARTITION BY <column_list>: This clause groups rows together based on the specified columns. Rows within each group will receive ranks.
- ORDER BY <column_list>: This one defines the order in which the rows within each partition will be ranked.
Steps for Deleting duplicate rows in SQL with RANK
The steps are explained here:
- Step 1 – Identify duplicates: The RANK() function assigns the same rank to rows with identical values in the PARTITION BY columns.
- Step 2 – Delete ranked duplicates: We can leverage a CTE to isolate the duplicates and then delete them based on the rank.
Example for RANK function
Suppose you have a table named Products with columns for product_id, name, and color. You want to remove duplicate rows in SQL by targeting the product entries based on name and color. Here’s the query:
WITH cte AS (
SELECT *, RANK() OVER (PARTITION BY name, color ORDER BY product_id) AS rank_num
FROM Products
)
DELETE FROM cte
WHERE rank_num > 1;Result: This query first creates a CTE named cte. It assigns a rank_num to each row in the Products table. The partitioning is done by name and colour, and the ordering is based on product_id. Rows with the same name and colour will receive the same rank_num.
Then, the DELETE statement removes rows from the CTE where rank_num is greater than 1, eliminating duplicate entries.
Before we wrap up, I have to mention the “human” side of things: ethical considerations in data visualisation. It’s incredibly easy to accidentally “lie” with a chart if your underlying SQL query is slightly off. Whether you are using SQL for business analysts to track quarterly growth or SQL sales data to project bonuses, transparency is key.
I always double-check my SQL query visualisation logic to ensure I’m not “cherry-picking” data, a common pitfall discussed in Alberto Cairo’s How Charts Lie. Remember, a data visualisation using SQL is only as honest as the person who wrote the SELECT statement.
FAQs on How to Delete Duplicate Rows in SQL
Usually, these examples help students understand how to delete duplicate rows in SQL. However, students and professionals still have a few queries. Here are some of the most frequently asked questions that can help you get better clarity.
How do I find duplicate rows in SQL?
You can use the GROUP BY clause with HAVING COUNT(*) > 1 to identify duplicate values in a table.
How do I delete duplicates without removing original data?
Use ROW_NUMBER() and delete only rows where the row number is greater than 1. This ensures one original record is preserved.
Which method is fastest to delete duplicate rows in SQL?
ROW_NUMBER() and CTE-based approaches are generally the most efficient for large datasets, while GROUP BY is useful for quick identification.
Can I prevent duplicate rows in SQL?
Yes, you can prevent duplicates by using PRIMARY KEY constraints, UNIQUE constraints and using proper data validation during the insertion of data.
Final Thoughts: Choosing the Right Way to Remove Duplicate Rows in SQL
Duplicate rows in your database can cause wasted space and skewed analysis. Cleaning up duplicates isn’t just about reclaiming storage space; it’s about trust. This article enables you to delete duplicate rows in SQL effectively.
We explored methods like GROUP BY with HAVING for basic tasks, and advanced techniques with ROW_NUMBER() and CTEs. Whether you’re using a quick GROUP BY Or a more elegant CTE, ensuring your data is unique, is the first step toward any analysis that actually matters. Once you’ve cleared the clutter, your queries run faster, and your insights carry more weight.
SQL is the language of data, but knowing how to delete a row is just the beginning of the conversation. The real magic happens when you stop managing data and start interpreting it – turning those clean tables into strategies that solve real-world problems.
If you’re ready to move beyond syntax and start building a career around these insights, our data science course (Postgraduate Program in Data Science Analytics) equips you with the skills to wrangle, analyse, and visualise data, making you an expert in data management. For a data-driven approach to managing your databases, it is a great place to start. It is designed to bridge the gap between “writing code” and “driving impact,” giving you the full toolkit you need to thrive in a data-driven world. Ready to dive in?