


Whether you are a fresher or an experienced data professional looking for better opportunities, attending an interview is inevitably the first step towards your dream career. Many of you might already have done a sneak peek into the world of data analytics through self-taught skills.
 Having a good grip on the subject matter will give you an edge over other candidates. Data Science Courses and certifications add more weightage to your profile.
Having a good grip on the subject matter will give you an edge over other candidates. Data Science Courses and certifications add more weightage to your profile.
Interviewers might ask situation-based questions to test your knowledge and crisis management skills. So, make sure that you answer these questions wisely and showcase your knowledge wherever possible, without going overboard.
Listed below are some important R programming, SQL, and Tableau interview questions and answers. Check them out!
R Programming Interview Questions
A handy programming language used in data science, R finds application in various use cases from statistical analysis to predictive modeling, data visualization, and data manipulation. Many big names such as Facebook, Twitter, and Google use R to process the huge amount of data they collect.
- Which are the R packages used for data imputation?
Answer: Missing data could be a challenging problem to deal with. In such cases, you can impute the lost values with plausible values. imputeR, Amelia, Hmisc, missForest, MICE, and Mi are the data imputation packages used by R.
- Define clustering? Explain how hierarchical clustering is different from K-means clustering?
Cluster, just like the literal meaning of the word, is a group of similar objects. During the process, the abstract objects are classified into ‘classes’ based on their similarities. The center of a cluster is called a centroid, which could be either a real location or an imaginary one. K denotes the number of centroids needed in a data set.
While performing data mining, k selects random centroids and then optimizes the positions through iterative calculations. The optimization process stops when the desired number of repetitive calculations have been taken place or when the centroids stabilize after successful clustering.
The hierarchical clustering starts by considering every single observation in the data as a cluster. Then it works to discover two closely placed clusters and merges them. This process continues until all the clusters merge to form just a single cluster. Eventually, it gives a dendrogram that denotes the hierarchical connection between the clusters.
SQL Interview Questions

If you have completed your SQL training, the following questions would give you a taste of the technical questions you may face during the interview.
- Point out the difference between MySQL and SQL?
Answer: Standard Query Language (SQL) is an English-based query language, while MySQL is used for database management.
- What is DBMS and How many types of DBMS are there?
Answer: DBMS or the Database Management System is a software set that interacts with the user and the database to analyze the available data. Thus, it allows the user to access the data presented in different forms – image, string, or numbers – modify them, retrieve them and even delete them.
There are two types of DBMS:
- Relational: The data placed in some relations (tables).
- Non-Relational: Random data that are not placed in any kind of relations or attributes.
Tableau Interview Questions
Tableau is becoming popular among the leading business houses. If you have just completed your Tableau training, then the interview questions listed below could be good examples.
- Briefly explain Tableau.
Answer: Tableau is a business intelligence software that connects the user to the respective data. It also helps develop and visualize interactive dashboards and facilitates dashboard sharing.
- How is Tableau different from the traditional BI tools?
Answer: Traditional BI tools work on an old data architecture, which is supported by complex technologies. Additionally, they do not support in-memory, multi-core, and multi-thread computing. Tableau is fast and dynamic and is supported by advanced technology. It supports in-memory computing.
- What are Measures and Dimensions in Tableau?
Answer: ‘Measures’ denote the measurable values of data. These values are stores in specific tables and each dimension is associated with a specific key. This helps to associate one piece of data to multiple keys, allowing easy interpretation and organization of the data. For instance, the data related to sales can be linked to multiple keys such as customer, sales promotion, events, or a sold item.
Dimensions are the attributes that define the characteristics of data. For instance, a dimension table with a product key reference can be associated with different attributes such as product name, color, size, description, etc.
The questions given above are some examples to help you get a feel of the technical questions generally asked during the interviews. Keep them as a reference and prepare with more technically inclined questions.
Remember, your attitude and body language play an important role in making the right impression. So, prepare, and be confident. Most importantly, structure your answers in a way that they demonstrate your knowledge of the subject matter.
Related Article:
https://imarticus.org/20-latest-data-science-jobs-for-freshers/

 SQL is used to access and manipulate data. It helps to store data, access whenever you need it, and retrieve if need be. SQL training will give you a much-required head start in the highly competitive job market.
SQL is used to access and manipulate data. It helps to store data, access whenever you need it, and retrieve if need be. SQL training will give you a much-required head start in the highly competitive job market.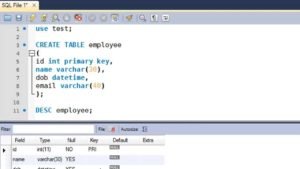 You may follow the steps given below to create a database.
You may follow the steps given below to create a database. Suppose you want to create a table with the following features:
Suppose you want to create a table with the following features: