


Machine learning has incorporated itself into your everyday lives to a great extent. This futuristic technology is empowering the world a little more with each passing day. Be it product recommendations at window shopping, fraud detection in the financial institutions, or content used by various social media platforms like Instagram, Facebook, and LinkedIn, everything uses machine learning algorithms. Simply put, machine learning is the future and it plays a very important role in our lives. And this is what makes machine learning so important.
It doesn’t matter in which field you’re in, you can take your career to the next level by taking a machine learning course. In this blog, we will discuss why you need to upskill with a machine learning course in 2022!
Why Machine Learning Course in 2022?
Machine learning has emerged as the most sought-after skill to have because of the increasing demand and the numerous benefits that it offers. Below are some reasons why a machine learning course is imperative in 2022:
1. Better Growth and Career Opportunities
A TMR report suggests that Machine Learning as a Service (MLaaS) is expected to rise from just $1.07 billion (in 2016) to a whopping $19.9 million by 2025. As you can see, this is not normal growth, the demand for ML is increasing exponentially.
If you’re planning to give a boost to your career then ML is the best tool to do that. Learning this course can help you become a part of both the global and contemporary world. Machine learning is not limited to just the IT industry, it has a strong foothold in areas like cyber security, medicine, image recognition, facial recognition, and many more. As more and more businesses are realizing that this technology is impacting their business, they are investing more and more in it.
For example, Netflix has put a reward of $1 million to anyone who can sharpen their machine learning algorithm by increasing its efficiency to 10%. This clearly indicates that even the slightest enhancement of ML algorithms can offer immense profit to the company, and thus more and more businesses are behind people who know ML.
2. Attractive Salaries
If you’re looking for a hike in your salary, then there is no better way than upskilling with a machine learning certification. Believe it or not, the best machine learning professionals earn as much as the popular sports personalities. According to Glassdoor.co.in, the average salary of a machine learning engineer is INR 10 lakhs per year ﹘ and it is their starting salary which eventually goes as high as INR 15 to 25 lakh per annum.
3. Lack of Machine Learning Can Be Harmful to Companies
Technological advancements are happening at the speed of lightning. And due to this, many corporations are left behind. Digital transformation is a vast field, and the fact is, there are not enough ML professionals to cater to increasing demands.
If we look at the stats, then a New York Times study that took place in 2017 stated that the total number of professionals in the AI and ML field was less than 10,000 people all across the globe.
This number is most likely to both increase and decrease. It is likely to increase because of the increased number of job opportunities that are being created, and it’s likely to decrease because more and more people are upskilling with ML every day.
The best part about upskilling with ML is that you don’t need to have an advanced set of skills and qualifications to take a machine learning course, anyone from any background can learn it.
Machine Learning is the Heart and Soul of Data Science
There is no doubt that data science rules the market because of its innovative viability and all-explaining nature. And machine learning is the heart and soul of this pioneering technology. By becoming proficient in ML, you can build your career in the field of data science as well. Note that many organizations have data scientists and ML engineers working hand in hand to complete highly demanding tasks. You can get exposure to the world of data science while having a chance to learn and work with industry-leading experts.
How to Get Started with Machine Learning in 2022?
Once you’ve made up your mind to become a machine learning expert, you’re just a step away from upskilling your career. All you need to do is find and enroll in the right machine learning course or certification program. With a combination of the right ML course, deduction, practice, and experience, you can soon become a machine learning professional.
The Bottom Line
That’s all about why machine learning is the best way to upskill in 2022. We have discussed everything from the importance of machine learning, its potential benefits, and why you should learn machine learning. It’s up to you to use this data to make the right decision.


 While you’re learning from a
While you’re learning from a 



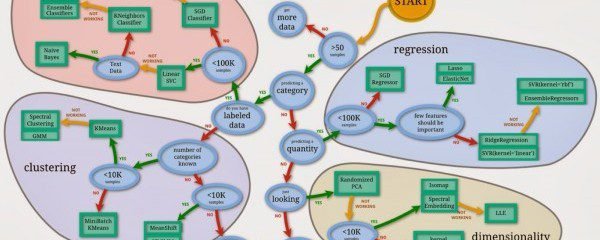 Sklearn precisely works as a one-stop solution that helps with importing, preprocessing, plotting, and predicting data.
Sklearn precisely works as a one-stop solution that helps with importing, preprocessing, plotting, and predicting data.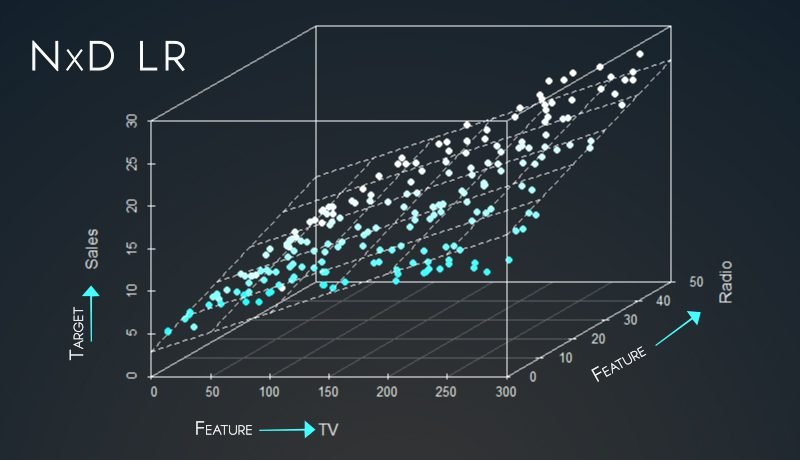
 If you’re a student in a neural network course or a
If you’re a student in a neural network course or a  The
The 