


Last Updated on 9 months ago by Imarticus Learning
Have you ever felt lost staring at endless rows of data?
Perhaps you’ve tried different algorithms but found yourself wondering, what is XGBoost, and how exactly can it help you?
You are not alone. Predictive modelling details can be overbearing to the uninitiated venturing into data science. Fortunately, though, there’s a clear way ahead.
This post provides an introduction to the XGBoost algorithm, simplifying the concept so you can confidently build your first predictive powerhouse.
Why XGBoost Emerged
A few years back, Kaggle competitions began witnessing a seismic shift. Algorithms once dominating leaderboards, like Random Forest and Support Vector Machines, gave way to a newcomer: the XGBoost algorithm.
XGBoost (eXtreme Gradient Boosting) is an open-source library designed for gradient boosting tasks.
Its aim is to provide a scalable, portable, and distributed gradient boosting framework (GBM, GBRT, GBDT). You are able to run XGBoost on one machine as well as across distributed systems. It can also integrate well with major processing frameworks, namely Apache Hadoop, Apache Spark, Apache Flink, and Dask.
Developed by Tianqi Chen in 2014, XGBoost rapidly gained fame for two reasons: remarkable speed and accuracy. During a recent data science course, participants using XGBoost models saw predictive accuracy climb to 89%, versus traditional models hovering around 74%.
But what triggered this rapid adoption? The short answer: performance. XGBoost cleverly manages large datasets and effectively handles complex non-linear relationships without slowing down.
What is XGBoost Exactly?
XGBoost stands for “Extreme Gradient Boosting,” which applies Gradient Boosting to create a machine learning library.
- It belongs to the broad category of ensemble learning, where various models team up to form a better and improved model.
- XGBoost creates multiple trees in succession, trying to improve upon the mistakes of the preceding trees, which is where the concept of boosting comes in.
- It has built-in parallel processing, which allows it to handle and analyze big data very fast.
- It is possible to customise different parameters in the algorithm to control how the model works on your given problem.
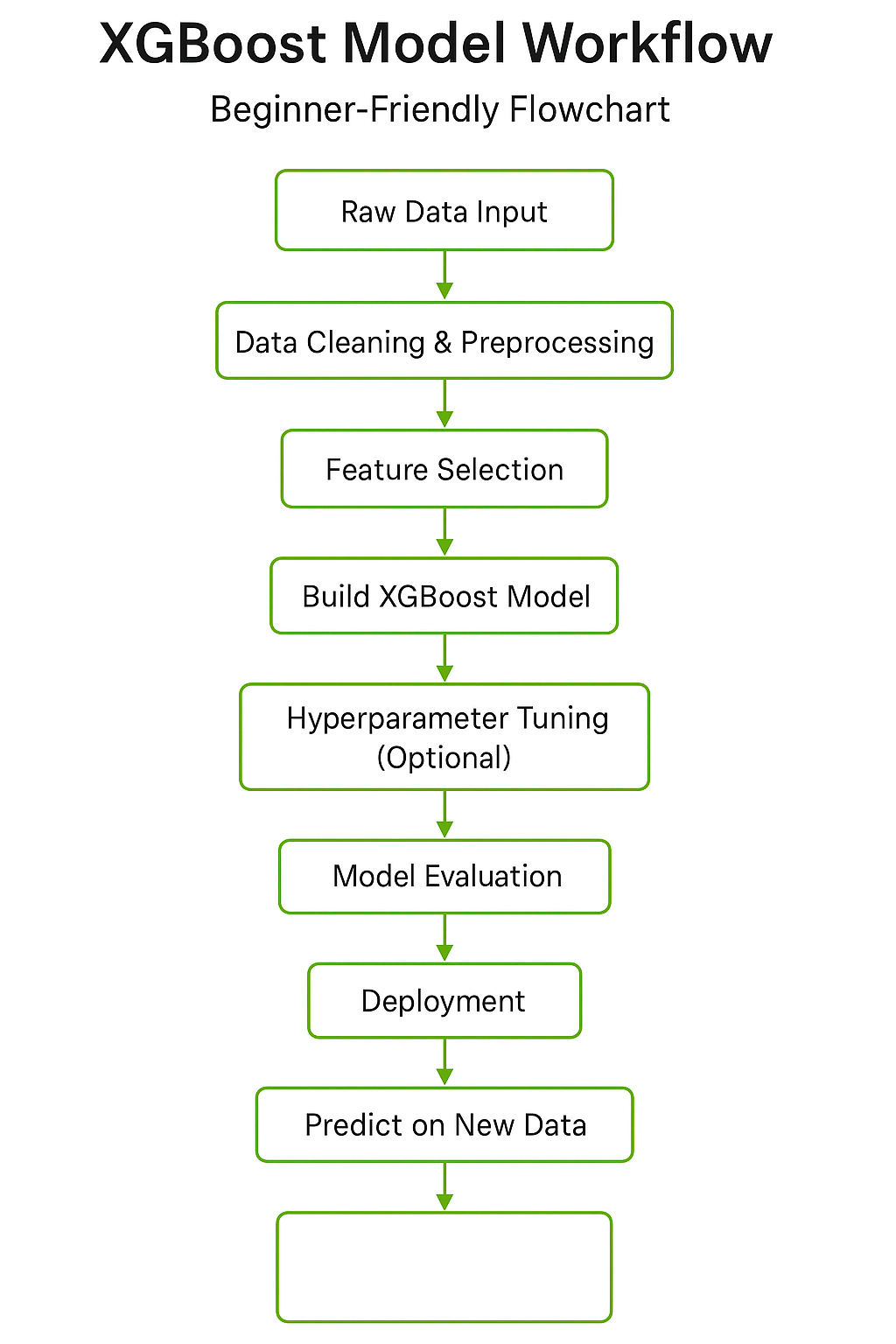
Technical Breakdown:
- Gradient Boosting: Builds sequential trees, learning from predecessor errors.
- Parallelisation: XGBoost cleverly processes data in parallel, reducing computation times.
- Regularisation: Prevents overfitting, enhancing prediction reliability.
In a recent retail project, we replaced a logistic regression model with an XGBoost model.
The result?
Conversion prediction accuracy jumped from 72% to 85% within just two weeks.
How to Implement XGBoost (Step-by-Step)
Here’s your step-by-step action plan to get started quickly:
Step 1: Installation
Open your Python console and type:
pip install xgboost
Step 2: Data Preparation
Organise data clearly. Missing values?
XGBoost handles them gracefully, but clean datasets still yield better results.
Step 3: Train Your First XGBoost Model
Start by preparing your dataset and splitting it into training and test sets. Then, use the XGBClassifier( ) from the XGBoost library to train your first model and evaluate its performance.
Step 4: Evaluate and Tune
Adjust hyperparameters using grid-search methods to boost accuracy further.
Why Should You Choose XGBoost?
If efficiency and accuracy matter to your career in data science, choosing XGBoost is simple logic. Companies—especially tech giants like Netflix and Uber—rely heavily on the XGBoost algorithm because results matter. Learning XGBoost now places you significantly ahead of peers relying on older models.
Extreme gradient boosting (XGBoost) is a feature selection method to identify key variables from high-dimensional time-series data while removing redundant ones. After isolating the most relevant features, we input them into a deep long short-term memory (LSTM) network to forecast stock prices.
Because the LSTM model handles sequential inputs, it effectively captured the temporal dependencies in the dataset and leveraged future context for improved predictions. Its layered structure allowed it to absorb more of the stochastic behaviour found in fluctuating stock prices, leading to more robust and realistic forecasting.
Why Data Scientists Prefer XGBoost
For anyone working in data science, XGBoost stands out due to its ideal combination of prediction performance and processing speed.
This claim isn’t just theoretical—benchmarking studies have consistently backed it. When trained and tuned well, XGBoost models can outperform other machine learning algorithms, especially when speed and accuracy are both critical.
Running complex XGBoost models on CPUs can be painfully slow. A single training session could take hours, particularly when building thousands of decision trees and testing dozens of hyperparameter sets.
- It speeds up common data prep tasks using a DataFrame interface, much like Pandas or scikit-learn.
- You can process, train, and even deploy models end-to-end, without costly data transfers between CPU and GPU.
- RAPIDS supports multi-GPU and multi-node setups, making it ideal for working with very large datasets.
XGBoost + RAPIDS: A Powerful Combination
The RAPIDS team collaborates closely with the developers of XGBoost, ensuring that seamless GPU acceleration is now built-in.
This integration allows:
- Faster model training
- Improved accuracy
- Better scalability across larger datasets
Thanks to GoAI interface standards, XGBoost can now import data directly from cuDF, cuPy, Numba, and even PyTorch—all without memory copies.
Using the Dask API, you can easily scale up to multiple GPUs or nodes, while the RAPIDS Memory Manager (RMM) ensures all processes share a single high-speed memory pool efficiently.
How GPU-Accelerated XGBoost Works
When using GPU acceleration, XGBoost performs:
- Parallel prefix sum scans to evaluate all possible splits in your data
- Parallel radix sort to optimise data partitioning
- Level-wise decision tree construction, enabling it to process the entire dataset in parallel
- This method dramatically speeds up each boosting iteration while maintaining high prediction accuracy.
Scaling with Spark and GPU-Accelerated XGBoost
NVIDIA also addressed the needs of large-scale enterprises by enabling XGBoost integration with Apache Spark.
The Spark-XGBoost release introduced distributed training and inference across Spark nodes, offering:
- Faster data pre-processing for massive datasets
- The ability to handle larger datasets in GPU memory
- Quicker model training and hyperparameter tuning
Whether you’re operating in the cloud or on-premise, GPU-accelerated XGBoost with Spark brings serious performance gains.
Quick Comparison: XGBoost vs Traditional Models
| Aspect | XGBoost | Random Forest |
|---|---|---|
| Speed | Fast | Moderate |
| Accuracy | High (89-92%) | Moderate (70-80%) |
| Scalability | Excellent | Limited |
| Complexity Handling | Strong | Average |
Postgraduate Programme in Data Science and Analytics with Job Assurance by Imarticus Learning
Prove yourself as a highly valuable asset to your company in the current job market by studying the Postgraduate Programme in Data Science and Analytics, a carefully designed programme by Imarticus Learning that provides you with important skills demanded of today’s data specialists.
Whether you are a new graduate or an early career professional with a technical background, this full course provides precisely the knowledge and practical experience required to become successful as a data scientist or data analyst.
The programme provides a strong course schedule including lessons in Python, SQL, Power BI, Tableau, and hands-on learning with practical analytics techniques, which makes you ready for the real world.
A postgraduate programme in data science and analytics ensures a job after graduating, and you will belong to our established network of more than 500 leading companies seeking data professionals, with doors wide open to at least 10 interview slots.
Students receive live sessions and hands-on training from experienced faculty, providing them with applicable industry-aligned experience to thrive in different roles in the data science space from the beginning itself.
Enrol now in the Imarticus Learning Postgraduate Programme in Data Science and Analytics and secure your dream job today!
FAQ
What is XGBoost?
XGBoost stands for Extreme Gradient Boosting, an efficient machine learning library for classification & regression tasks.
Is the XGBoost algorithm difficult for beginners?
Yes, it is initially challenging, but approachable with structured guidance.
Can XGBoost handle missing data?
Yes, it effectively manages missing values.
Why is the XGBoost model popular in data science courses?
High accuracy and straightforward implementation make it ideal for beginners.
How does XGBoost avoid overfitting?
XGBoost uses regularisation parameters and early stopping techniques.
Does learning XGBoost require advanced programming skills?
Basic Python proficiency is sufficient to start mastering XGBoost.
Is XGBoost compatible with Python and R?
Absolutely, it integrates seamlessly with both languages.
