


Last Updated on 7 months ago by Imarticus Learning
In the hectic era of data science, statistical concepts are the pillars of wise decision-making, precise model forecasts, and wise data stories. Machine learning model construction or riding business metrics, sound knowledge of statistics is essential. Having an ability to grasp basics of statistics for data science, in this hectic competitive data-driven enterprise era, is an absolute requirement for anyone in this profession.
In this blog, we’ll explore the important statistical concepts for data scientists, and basics of statistics for data scientists from foundational ideas to the more nuanced statistical methods in data science. We’ll also discuss how these concepts apply practically and why every aspiring professional must-know stats for data science to thrive in their career.
Why are Statistical Concepts Important in Data Science?
Statistics is not merely something in your school background. It’s the foundation of data science. Any algorithm, any prediction, any correlation – they’re all built on statistical theory. From machine learning statistics to running data experiments, data scientists use stats to decode and validate results.
Statistical Concepts Provide:
- Order of Data Interpretation
- Validation
- Inventive Summaries of Trends
- Platform for Hypothesis Testing
- Predictive and Probabilistic Tools
Now, let’s talk about the key statistics for data science that any professional needs to know.
Descriptive Statistics: The Foundation
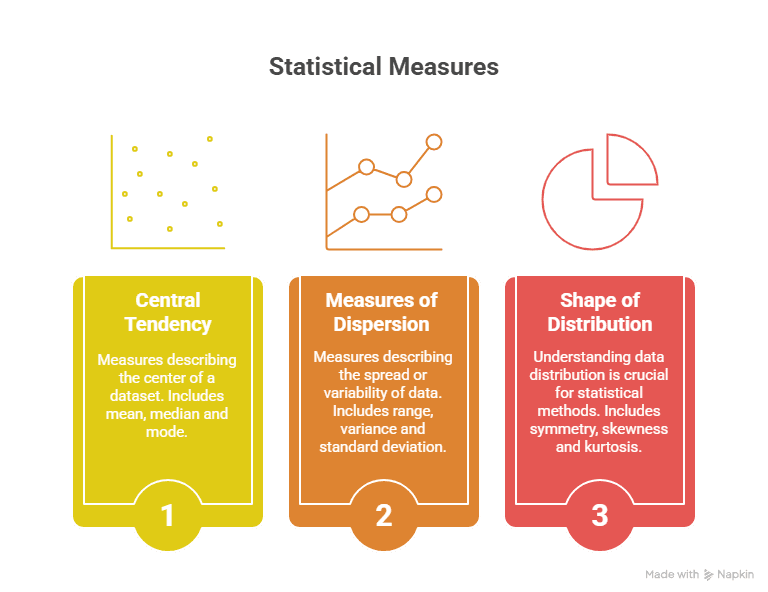
There is descriptive statistics in every single dataset – they’re measures that aptly summarize data.
Key Measures Include:
- Mean, Median, Mode: Simple measures of central tendency.
- Standard Deviation & Variance: Dispersion measures that reflect data spread.
- Skewness & Kurtosis: Distribution shape measures.
These factors enable analysts to immediately understand the data structure prior to getting to dig deeper.
Probability: Measuring Uncertainty
No discussion of statistical concepts would be complete without a discussion of probability. It is the foundation of decision-making and predictive models.
Key Ideas:
- Probability Distributions such as Binomial, Normal, and Poisson
- Conditional Probability & Bayes’ Theorem
- Monte Carlo Simulations
Statistics and data science’s probability enables data scientists to put numbers on uncertainty and provide more informed estimates.
Inferential Statistics: Drawing Conclusions from Samples
While descriptive stats enable you to summarize your dataset, inferential stats enable you to make conclusions beyond your dataset.
Core Methods:
- Confidence Intervals
- Hypothesis Testing (Z-test, T-test)
- Chi-square Tests
- ANOVA (Analysis of Variance)
These are the fundamentals of running A/B testing, customer testing, and model testing on real-world data science pipelines.
Regression Analysis: Building Predictive Models
Perhaps the most ubiquitous statistical technique of data science, regression assists in assessing association and predicting future trends.
Types of Regression:
- Linear Regression: most suitable for continuous prediction
- Logistic Regression: applied to classification problems
- Ridge/Lasso Regression: regularized forms for greater accuracy
Regression is one of the data science stats staples because it yields insights into feature significance and the ability to forecast.
Bayesian Thinking: A Modern Approach to Inference
Bayesian statistics are increasingly applied due to its inherent handling of uncertainty.
Concepts Include:
- Prior and Posterior Probability
- Bayesian Inference
- Bayesian Networks
The majority of statistics and data science work, particularly in recommendation systems and NLP, is based on this paradigm.
Sampling Techniques: Working With Real-World Data
Sampling allows for effective handling of big data in the form of representative samples.
Important Techniques:
- Random Sampling
- Stratified Sampling
- Systematic Sampling
- Bootstrap Sampling
Sampling is crucial to prevent biases and keep the model pure.
Central Limit Theorem (CLT): Statistical Bedrock
CLT tells us why most statistical methods perform so well. CLT tells us that with the population size being large enough, the sampling distribution of the mean will be very close to a normal distribution.
It’s used in most statistical concepts and is the fundamental thought process of hypothesis testing.
Feature Selection and Correlation
It is absolutely critical to recognize the behavior of correlation and its limitations while selecting features for a model.
- Pearson Correlation Coefficient
- Spearman’s Rank Correlation
- Multicollinearity Analysis (VIF)
Variable selection is essential to design effective and efficient ML models.
Time Series Analysis: Tracking Data Over Time
Applied in financial forecasting, trends in sales patterns, and predicting stock prices.
Techniques:
- Moving Averages
- ARIMA Models
- Exponential Smoothing
These statistical values enable one to understand the pattern of variable change over time.
Imarticus Learning’s Data Science Course: Practical Stats in Action
If you want to apply all these key statistical concepts to data scientists in live projects, the Postgraduate Program in Data Science and Analytics by Imarticus Learning simply does that.
This 6-month program includes:
- Job-oriented Curriculum: Python, SQL, Tableau, and statistics
- 10 Interview Guarantees: With 2000+ hiring partners
- Projects Based on Real-world Applications: 25+ projects with statistical applications
- Live Learning & Career Services: Resume development, hackathons, mentorship
22.5 LPA top salary and 52% mean raise, this is the best way to study statistics for data science with job assurance.
Real-world Applications of Statistical Concepts
In Machine Learning:
Control by regression, classification, and probability supervise learning
Statistical distances are utilized in clustering and density estimation
In Business:
- A/B marketing campaign testing
- Forecasting sales trend analysis
In Healthcare:
- Biostatistics in clinical trials
- Risk prediction models
These machine learning ideas equip professionals across domains of life.
Challenges in Learning Statistics
Statistics are strong, but students are afflicted by:
- Too complicated mathematical notation
- Scary jargon
- Lack of ability to connect practice and theory
That is why a structured course like Imarticus’ Data Science Course is necessary.
Tips to Learn Statistics for Data Science
- Begin with Descriptive Stats and Visualisations
- Python Packages such as Statsmodels & Scipy
- Apply principles to actual datasets
- Mentor-guided courses
- Hackathons and competition
FAQs
1. Why are statistical concepts important in data science?
They form the basis of all analysis models and methods and are employed to retrieve conclusions and test predictions.
2. What are the most important statistical methods for data scientists?
Descriptive statistics, probability, regression, and hypothesis testing are the stars of the show.
3. Is it necessary to be a math expert to learn data science?
No, but you do have to know elementary statistics.
4. How can I apply statistics in real-world projects?
Use them for A/B tests, machine learning model validations, and business analytics projects.
5. Are there tools that make learning statistics easier?
Yes, Python (Scipy, Statsmodels), Excel, and R make statistical analysis easier.
6. Can I learn statistics without coding?
You can learn theory, but in today’s life, you have to know basic programming.
7. How does the Imarticus course cover statistics?
It involves practical exposure of Python, SQL, and introductory statistical theory through case studies and projects.
Conclusion
Statistics principles aren’t something that you decide to learn – it’s a necessity. If you’re looking for trends within patterns or creating machine learning models, core statistics for machine learning, statistics in data science helps you take numbers and turn them into findings. Bayesian inference to hypothesis testing, every principle gets you one step nearer to becoming an excellent data scientist.
Ready to start your odyssey? With Imarticus Learning Postgraduate Programme in Data Science and Analytics, not only do you learn all this, but get to implement it on real-time projects, with 100% job guarantee and unparalleled career advice.
