



Last updated on May 15th, 2026 at 02:51 pm
Data is the foundation of the Data Science function. With businesses generating a lot of unstructured data, machine learning frameworks help with handling unlabelled data. The entire domain of Unsupervised Learning under machine learning works on unlabelled data.
As we want to understand how data is organized under machine learning, clustering plays an integral role in this function. Clustering can also handle labelled data apart from handling unlabelled data. As the name suggests, clustering is used for grouping similar data together. One such technique of clustering is known as K-Means Clustering. It is one of the most common forms of clustering.
What is K-Means Clustering?
K-Means Clustering is a type of unsupervised machine learning algorithm used to group similar data points. The goal of the algorithm is to partition a dataset into K clusters, where each cluster contains similar data points. The number of clusters (K) is specified by the user and is one of the inputs to the algorithm.
The algorithm works by first randomly initializing K centroids, which are the centre points of the clusters. The data points are then assigned to the closest centroid based on their Euclidean distance. After all data points have been assigned to a centroid, the centroid positions are recalculated based on the mean position of the data points in the cluster. This process is repeated until the centroid positions no longer change or a maximum number of iterations is reached.
The K-Means Clustering algorithm is sensitive to the initial placement of the centroids, so it’s common to run the algorithm multiple times with different initial centroid positions to ensure that the final clusters are stable.
Use case of K-Means Clustering
K-Means Clustering is a widely used algorithm in many fields, including image and speech recognition, market segmentation, and anomaly detection. It’s also used as a preprocessing step in other machine-learning algorithms.
The key goal of K-Means Clustering is not just to make clusters but to create useful and meaningful clusters. It is critical that the data points in a cluster and closer together and far away from other clusters.
How does K-Means Clustering work?
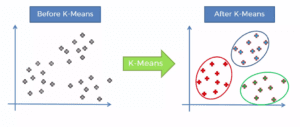
The key goal of K-Means Clustering is to find out clusters in the provided dataset. It can either be done by trial and error where the value of K keeps changing till we can create the best clusters. Another method is the elbow technique to find out the value of K. The value from the centroid and the number of centroids are critical for the proper functioning of this method. Accordingly, it uses those points to the corresponding centroid where the distance is the least.
Benefits of K-Means Clustering
There are several benefits of K-Means Clustering. The key advantages of K-Means Clustering are as follows:
Scalability
One of the key advantages of K-Means Clustering is its scalability, it can handle large datasets, and also it’s computationally efficient.
Pattern Identification
It can also be used to identify patterns and structures in the data that are not immediately obvious.
Adaptable
The K-Means Clustering can be adapted to new examples easily. As a result, it is one of the most common methods of handling unlabelled data.
Drawbacks of K-Means Clustering
Along with several advantages, there are some drawbacks of K-Means Clustering. The key drawbacks of K-Means Clustering are as follows:
Size of Clusters
One major drawback of the K-Means Clustering algorithm is that it assumes that the clusters are spherical and equally sized.
Density
K-Means Clustering also assumes that the data points within a cluster are dense, meaning that there are no large gaps between data points. This can lead to poor results if the data does not meet these assumptions.
Specific Knowledge
K-Means Clustering requires us to specify the number of clusters (K) in advance, which can be a challenge when the number of clusters is not known. Also, It’s not guaranteed that the final clusters will be optimal, or even meaningful, for the problem at hand.
It is important to pre-process the data in the case of K-Means Clustering. We need to convert the dataset into numerical values in case data is not already present in the prescribed format before calculations can be performed. We should also understand that applying feature-reduction techniques would improve the speed of the process.
IIT Roorkee Machine Learning Certification Course
The Machine Learning Certification Course from iHUB DivyaSampark at IIT Roorkee and Imarticus Learning can help us learn about K-Means Clustering and other techniques to help us build a data scientist career. The Machine Learning Certification Course from IIT Roorkee covers several modules which help provide an in-depth understanding of various topics in the field of data science and machine learning. The IIT Roorkee Machine Learning Certification Course has been designed by IIT faculty for early and mid-level professionals that provide live training by IIT faculty and campus immersion opportunity at IIT Roorkee.