



Last updated on May 15th, 2026 at 02:57 pm
A key component of data-driven research and engineering is designing and modelling data for ML-driven systems. Understanding the significance of developing and modelling data for ML-driven systems is crucial, given the expanding use of machine learning (ML) in many industries.
A subset of artificial intelligence (AI) known as machine learning involves teaching computer experts to learn from data and form conclusions or predictions. Since ML-driven systems are built and trained on data, the ML model and algorithm must also be adjusted when the underlying data changes. To become a data analyst, enrol in a data science course and obtain a data analytics certification course.
Data Engineering
Data engineering is designing, creating, and maintaining the infrastructure and systems that enable businesses to gather, store, process, and analyse vast amounts of data. Data engineers are responsible for building and managing the pipelines that carry data from multiple sources into a data warehouse, where data scientists and analysts can convert and analyse it.
Techniques for Data Cleaning and Preprocessing
Data cleaning and preprocessing are key techniques in data engineering that comprise detecting and rectifying flaws, inconsistencies, and missing values in the data. Some typical techniques for data cleaning and preprocessing include:
- Removing duplicates
- Handling missing values
- Standardising data types
- Normalising data Handling outliers
- Feature scaling
Tools for Data Engineering
There are numerous tools available for data engineering, and the most often used ones vary depending on the firm and the particular demands of the project. Some of the most prominent data engineering tools include:
Python: It is a powerful and easy-to-use programming language commonly employed for data engineering projects.
SQL: A language used for managing and accessing relational databases.
Apache Spark: A distributed computing solution that can rapidly process enormous volumes of data.
Amazon Redshift: A cloud-based data warehousing system that can handle petabyte-scale data warehouses.
PostgreSQL: An open-source relational database management system.
MongoDB: A NoSQL document-oriented database.
Apache Kafka: A distributed streaming infrastructure that can manage enormous volumes of real-time data.
Apache Airflow: A programmatic writing, scheduling, and monitoring platform.
Talend: An open-source data integration platform.
Tableau: A data visualisation programme that can connect to multiple data sources and build interactive dashboards.
Data Modelling
Data modelling is developing a visual representation of a software system or sections of it to express linkages between data. It entails building a conceptual representation of data objects and their connections. Data modelling often comprises numerous processes, including requirements collecting, conceptual design, logical design, physical design, and implementation.
Data modelling helps an organisation use its data efficiently to satisfy business demands for information. Data modelling tools aid in constructing a database and enable the construction and documenting of models representing the structures, flows, mappings and transformations, connections, and data quality. Some standard data modeling tools are ER/Studio, Toad Data Modeler, and Oracle SQL Developer Data Modeler.
There are several types of data models used in data modelling. Here are the most common ones:
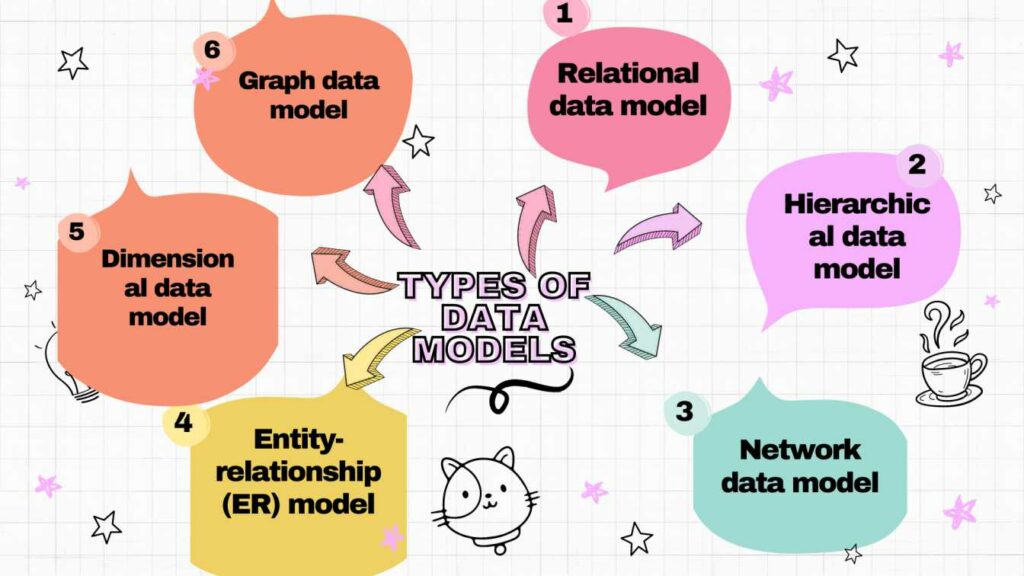
- Relational data model: This paradigm groups data into “relations” tables organised in rows and columns. All the rows or “tuples” have a series of connected data values, and the table name and column names or characteristics explain the data.
- Hierarchical data model: This model represents one-to-many relationships in a tree-like structure. It is useful for displaying data with a clear parent-child connection.
- Network data model: This model is similar to the hierarchical model but allows for many-to-many relationships between nodes. It is handy for representing complex data relationships.
- Entity-relationship (ER) model: This model represents entities and their relationships to each other. It is effective for describing complex data relationships and is often used in database architecture.
- Dimensional data model: This model is used for data warehousing and business intelligence. It organises data into dimensions and metrics, allowing for easier analysis and reporting.
- Graph data model: This model represents data as nodes and edges, enabling complicated relationships to be easily expressed and evaluated.
Machine Learning
Machine learning is a discipline of artificial intelligence that focuses on constructing algorithms and models that allow computers to learn from data and improve their performance on a specific job. Machine learning algorithms utilise computer technology to learn straight from data without depending on a predetermined equation as a model.
Machine learning may be roughly classified into two basic types: supervised and unsupervised. Supervised learning includes training a model using known input and output data, enabling it to make predictions for future outputs. In contrast, unsupervised learning identifies latent patterns or underlying structures within incoming data.
Machine learning starts with data obtained and produced to be utilised as training data. The more info, the better the tools. Machine learning is highly adapted for scenarios involving masses of data, such as photos from sensors or sales records. Machine learning is actively applied today for various purposes, including tailored ideas on social networking sites like Facebook.
Integration of Data Engineering, Data Modelling, and Machine Learning
For data science initiatives to be successful, data engineering, data modelling, and machine learning must all work together. Data modelling guarantees that data is correctly structured and prepared for analysis, whereas data engineering creates the infrastructure and basis for data modelling and machine learning. Machine learning algorithms leverage data from data engineering and modelling to extract insights and value from data.
Examples of how data engineering, data modelling, and machine learning may be coupled include as follows:
- Data engineers’ creation of data pipelines allows for the training and prediction of machine learning algorithms using data.
- In addition to ensuring that the data is appropriately arranged and displayed, data modelling may be used to develop a model that accurately reflects the data utilised by machine learning algorithms.
- Data analysis and insight-providing capabilities of machine learning algorithms may be used to enhance data engineering and data modelling procedures.
Conclusion
The success of ML-driven systems is based on the engineering and modelling of data used in these systems. While smart data modelling enables the development of strong machine-learning models that can make accurate predictions and generate insightful information, effective data engineering ensures that the data is clean, relevant, and accessible.
Imarticus Learning provides a Postgraduate Program in Data Science and Analytics that is meant to assist learners in creating a strong foundation for a career in data science or a career in data analytics. The data science training curriculum is 6 months long and includes Python, SQL, data analytics, machine learning, Power BI, and Tableau. The data analytics course also provides specific programmes to focus on various data science employment opportunities. Upon completing the data science course, learners receive a data science certification from Imarticus Learning.