



Last updated on May 15th, 2026 at 02:25 pm
What is Data Science?
Data plays a major role in every organization as it helps in making decisions based on facts, statistics, and trends. Data science helps to trace insights from the raw data generated, which in turn is used to make major business decisions. Implementing Data Science in business has several advantages.
- It helps in reducing risks and identifying fraud models. Data scientists are trained to identify data that stands out in some way and they use methodologies to predict fraud models along with creating alerts every time unusual data is identified.
- It helps organizations in identifying when and where the products best sell. This helps the organization to deliver the right products at the right time as per the customers’ needs.
- It helps the sales and marketing teams to understand their audience well and helps with providing personalized customer experiences.
Why Data Science Needs DataOps?
Data scientists deal with searching for data, labeling, cleaning, and performing other tasks that consume a lot of time. Especially if the business has to maintain a backlog legacy, then the amount of data keeps multiplying every year. This is where the need for DataOps rises.
DataOps involves collaboration, automation, and continuous innovation to data within a data-driven environment. Just like software can not be expected to provide exact results outside its live environment, data projects may also tend to behave similarly and may have to be reworked completely to make it work in a production environment. It also has to be continuously monitored even after deployment. Which makes it even more necessary to implement DataOps in a Data Science project.
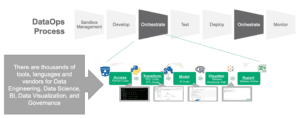 DataOps plays a major role in building best practices throughout a function. Through continuous production, DataOps helps organizations to deliver value to a range of stakeholders.
DataOps plays a major role in building best practices throughout a function. Through continuous production, DataOps helps organizations to deliver value to a range of stakeholders.
Another significance of using DataOps in Data Science is Automation. Data moves through a particular process within an organization. While Data is entered in one form, it does not exist in the same form. Data scientists have to build data pipelines, test, and change them before data is deployed.
Making use of DataOps best practices, you can get a constant stream of data flowing through the pipelines. Which in turn, helps to attain real-time insights from the data. This ensures to reduce the time taken in converting raw data into Valuable information.
Combining Machine Learning with DataOps helps in maintaining a continuous workflow through internal communication. With this, the data quality can be controlled through version control, constant development, and integration. Combining ML also improves the insights and has a great potential for extracting value from DataOps.
Introducing DataOps in the organization also means changes in the work process. It builds a new ecosystem with consistent communication between the departments. Employees of each department work together, in real-time, sharing a common goal.
Therefore, using DataOps in Data Science ensures to develop projects keeping in mind the business impact along with delivering it in a way that the management can understand.
Why Data Science Course?
The Data Science course covers a mix of topics like mathematics, Tools, Machine Learning techniques, Business Acumen, and several algorithms. The main principle behind Data Science is finding patterns from gigabytes of raw data collected.
In today’s competitive world, more and more organizations are opening up to big data, and the need for data scientists is also on the rise. They get exciting opportunities to work on and also get to come up with solutions for businesses.