In today’s data age, enrolling in a data science course is not only an educational process—it is a passport to entry into one of the most remunerative and fulfilling career options of the digital age. This course, as a career change or new college graduate, has the potential to turn you around from zero to hero by making you more hands-on, job-guaranteed, and analytics-confident.
The demand for data professionals is through the roof. Companies are making decisions on the basis of data more and more, and the world is in need of capable data scientists in increasing and increasing numbers every year. You have our Postgraduate Programme in Data Science and Analytics with a 100%-job-assurance-guaranteed course, 25+ projects, 10+ tool exposure, and mentorship that actually makes your journey, all under Imarticus Learning.
Let’s discuss how this data science course can be your gateway to a lucrative analytics and tech career.
What is a Data Science Course?
Understanding the Basics of a Data Science Course
A data science course is technique and tool-based with prerequisite courses in Python, SQL, Tableau, and Power BI. The data science for beginners courses to professionals who can work in heavily regulated industries through intense project work, placements, and training.
You will learn:
- Data wrangling and collection
- Exploratory data analysis
- Machine learning algorithms
- Predictive modeling
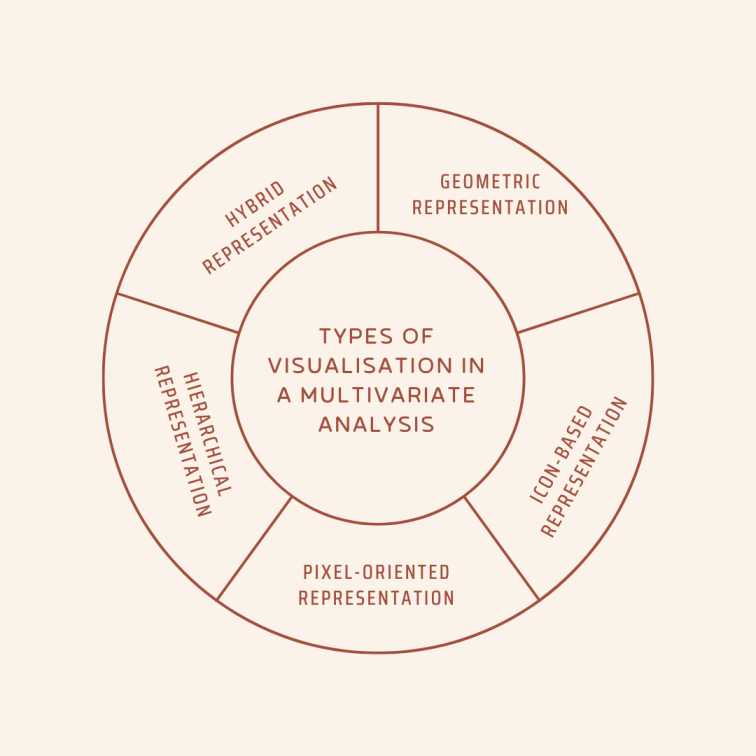
- Visualisation using BI tools
- Communication of results to stakeholders
Wherever it is an on-campus or online data science course, the program supports multi-styled learning to yield results that matter.
Why Learn Data Science Today?
Exploring the Scope for a Career in Data Science
The world is generating data at a bewildering pace—2.5 quintillion bytes per day, actually. The data itself is not necessarily useful unless utilized in the proper manner, and that’s where data science learning courses are of use.
Why learning data science is a good idea:
- Massive career opportunities in financial services, health care, retailing, and technology industries
- High paying salaries with starting offers of 4–7 LPA and even 22 LPA and higher for working professionals
- Offshore demand guarantees opportunities overseas
- Develops reasoning skills, a key 21st-century skill
Curriculum Overview: Learn the Right Tools
What Will You Learn in a Data Science Course?
A proper online course in data science will have theory, application, and employability-based modules. Imarticus’ course includes:
- Python for data manipulation
- SQL for database management
- Machine Learning for prediction
- Power BI & Tableau for visualization
- 25+ Projects to apply concepts to actual projects
Students are exposed to Imarticus COE Hackathons and case studies that hone technical as well as business acumen. The combination makes you stand out in the job market.
Job Assurance and Placement Success
How a Data Science Training Program Ensures Career Success
Job placement is the biggest fear barrier that students face. At Imarticus Learning, you are assured of:
- 100% Job Guarantee
- 10 Interview Guarantees
- 2000+ Recruitment Partners
- 52% Average Pay Rise
- Max Package of max 22.5 LPA
This data science course is results-driven. You also receive:
- Resume guidance
- Interview preparation
- Personal guidance
- Career mapping sessions
This type of guidance benefited over 15,000 students in getting placed at top companies.
Career Opportunities After a Data Science Course
What Jobs Can You Get After This Course?
It is not a course. It is a career launcher for roles such as:
- Data Scientist
- Business Analyst
- Data Analyst
- Machine Learning Engineer
- Business Intelligence Specialist
- Analytics. Manager
- Data Science Consultant
They will be in sectors as broad as banking and e-commerce and will go up in number even more as more businesses are adopting data-driven strategies.
Who Should Enrol in This Course?
Is This Course Right for You?
The data science course is best suited for:
- Recent graduates holding engineering or technical diplomas
- Working professionals with less than 3 years of work experience
- Career transition candidates, who need to shift to an analytics career.
- Professionals with data logical and analytical problem-solving skills
Being a low coding skill or a beginner coder, instructor-led training is given in this course.
Real Projects. Real Skills.
Why Projects Matter in a Data Science Course
You don’t learn theory—you implement real solutions. Imarticus provides:
- 25+ Interactive Projects
- Simulation for Ethical Banking
- AML Detection Systems
- Analytics on Business Use-Case
The projects are business simulated problems and prepare you to derive value out of data in high-risk environments.
Learn Online or in the Classroom
Flexible Learning Modes with Equal Impact
Whether you are taking online classes or want classroom sessions, the data science course is made to be interactive. From live expert sessions and peer group work to round-the-clock learning access, you experience the best of both worlds.
- Weekday batches to suit working professionals
- Interactive modules and peer reviews
- Real-time doubt resolution
What Makes Imarticus the Best?
Key Reasons to Choose Imarticus to Become a Data Scientist
- Best Education Provider in Finance (Elets World Education Summit 2024)
- 1000+ Placement Partners – top MNCs
- 60%+ Top-Tier College Students
- Best Placement History in 1200+ Batches
While choosing a course in data science, choose the one with placement figures, industry acceptance, and student success stories.
What Our Alumni Say?
Some of the new data science graduates have secured jobs as senior analysts or BI experts in mere 6 months. All thanks to Imarticus’ career counseling, networking, and technology-driven training.
This is what one of them has to say:
“The game-changer was career mentoring and live projects. I got placed within weeks of graduation!!”
Key Benefits Recap
- 6-Month Intensive Program
- Live Online & Classroom Training
- 25+ Projects & Hackathons
- 10+ Tools Covered
- 10 Interview Job Guarantees
- 100% Job Guarantee
You will learn how to be a master in data science from the ground up and how to ensure you apply that skill for placement in a best-fit job.
FAQs
1. Is this course suitable for beginners?
Yes. Syllabus begins from the beginning and is best for technical background or analytical type of person.
2. Do I need coding experience?
No experience in coding is required, but that is always welcome. Python and SQL are taught from the very beginning in the course.
3. Will I receive job placement assistance?
Yes. The course promises me 100% job placement guarantee and 10 guaranteed interviews.
4. What tools will I learn?
You will be learning Python, SQL, Power BI, Tableau, etc.
5. How long is the course?
Course duration is 6 months with live classes, projects, and exams.
6. Can I join if I’m working full-time?
Yes. Time slots of weekday batches are also convenient for professionals.
7. What kind of roles will I be eligible for?
Data Scientist, Analyst, BI Specialist, ML Engineer, and more analytics jobs.
Conclusion: Take the First Step Today
Selecting a data science course is a career-defining decision. From learning the new tools to job guarantee, this is one decision that will change your life. Imarticus Learning’s course is not learning—It’s doing, showing, and expanding. Join the over 15,000 students who already changed their lives. Your data science journey starts.